C++ 性能优化笔记
malloc / new
malloc 不会自动调用构造函数,通过绕过构造函数和析构函数,直接用底层手段手动控制对象的生命周期,避免额外的函数调用开销。
1 | class Person { |
1
2
调用构造函数
1
调用析构函数
移动构造 / 拷贝构造
移动构造 仅接管指针(原对象置空)
ClassName(ClassName &&obj)
{this.data = obj.data; obj.data = nullptr}
拷贝构造 深拷贝,分配新内存(复制),性能差
ClassName(const ClassName &obj)
{this.data = new int(*obj.data)}
emplace_back() / push_back()
push_back() 先创建元素,再将这个元素拷贝或者移动到容器中,性能差。emplace_back() 直接在容器尾部创建元素,无拷贝或移动元素的过程。
深拷贝 / 浅拷贝
浅拷贝 拷贝指针地址,共享资源。
深拷贝 拷贝资源内容,各自拥有自己的资源,性能差。
堆 / 栈
- 字符串拼接,
string(堆) /char(栈)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
// 测试用例:N次字符串拼接
// 方法1:std::string
void funcString(benchmark::State& state){
for (auto _ : state){
std::string s;
for(int i=0; i<N; ++i) s += "a"; // SSO优化初期,后期堆分配
benchmark::DoNotOptimize(s);
}
}
BENCHMARK(funcString);
// 方法2:char[](栈)
void funcCharstack(benchmark::State& state){
for (auto _ : state){
char arr[N]; // 危险!可能栈溢出
for(int i=0; i<N; ++i) arr[i] = 'a';
benchmark::DoNotOptimize(arr);
}
}
BENCHMARK(funcCharstack);
// 方法3:char*(堆)
void funcCharheap(benchmark::State& state){
for (auto _ : state){
char* ptr = new char[N];
for(int i=0; i<N; ++i) ptr[i] = 'a';
benchmark::DoNotOptimize(ptr);
delete[] ptr;
}
}
BENCHMARK(funcCharheap);
// 方法4:std::vector<char>
void funcVectorChar(benchmark::State& state) {
for (auto _ : state) {
std::vector<char> vec;
vec.reserve(N); // 提前分配堆空间,避免多次扩容,提升性能
for (int i = 0; i < N; ++i) vec.emplace_back('a');
benchmark::DoNotOptimize(vec);
}
}
BENCHMARK(funcVectorChar);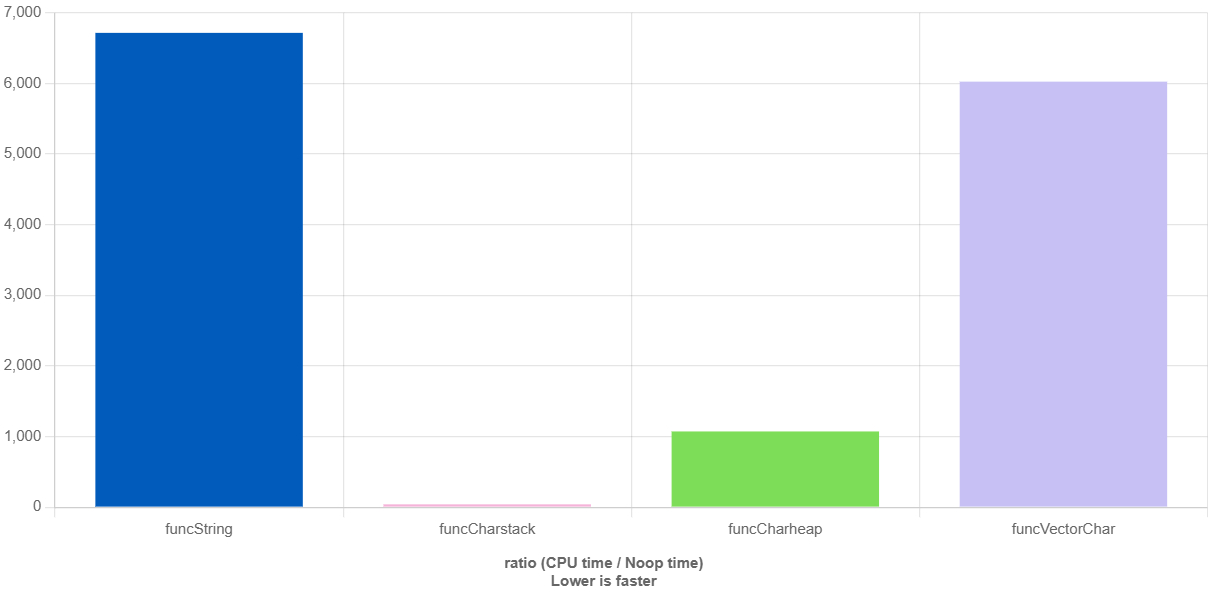
性能测试网站
显然耗时string≈vector<char>>char*>char[]
另外vector在未提前reserve()空间的情况下,性能基本与string相同,提前分配堆空间后提升了约10%的速度。
多线程
lock_guard / unique_lock
lock_guard 仅自动加解锁。unique_lock 可手动加解锁,支持延迟锁定,可用条件变量 condition_variable ,性能差。
atomic / std::mutex
std::atomic 底层用 CPU 指令,适合单个变量。std::mutex 适合多个变量同步,性能差。
内存池
减少频繁调用系统级内存分配函数(如 malloc/new)的开销
系统分配一次内存(尤其是小块)会涉及锁、页表管理、对齐等,代价很高。
内存池一次性向系统申请一大块内存,再在池内划分出小块供程序使用。加快内存分配速度
池内的分配通常只是指针移动或从空闲链表取节点,非常快,几乎 O(1)。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 逸人の博客!
相关推荐

2025-10-04
C++ 笔记
杂记
2025-08-30
运算符重载与函数对象
函数对象:使用方式看上去像函数,但实际是类的一个对象;是因为类重载了“()”运算符,所以让对象使用的方式看起来是函数,即对象后面的括号像函数一样调用。 12345struct Adder { // 1. 类重载了 operator() int operator()(int a, int b) const { return a + b; }};Adder add; // 2. 函数对象int r = add(3, 4); // 调用函数对象 友元函数不是类的成员函数,但它可以访问类的私有和保护成员,为操作符重载提供了灵活性。 123friend std::ostream& operator<<(std::ostream& os, const Student& s) { return os << '[' << s.id << ','...
2025-08-17
std::move 与 std::forward 以及左右值
https://www.bilibili.com/video/BV1ZViMBGECR/?spm_id_from=0.0.search.video_card.click&vd_source=11db1d1a077558e043cecb028334f12a左值引用 & 就是别名 值类别参考 lvalue: 左值,可取地址,如变量名。 prvalue: 纯右值,如 int(42) 临时量。 xvalue: 将亡值, 如表达式 std::move(obj)。 纯右值和将亡值都统称右值(rvalue),可以是不具名的临时变量,可以是即将离开作用域或被 move 的类型。左值和将亡值都属于泛左值。 Attention 值类别(value category)只看“表达式的静态属性”,跟对象本身的状态无关。变量本身没有值类别,只有表达式才有。 12int x = 42;decltype(auto) b = std::move(x); 当以后写 b 这个标识符时,它所在的表达式是左值(因为具名变量都是左值表达式),但它的声明类型仍然是 int&&。 s...
2025-08-05
C++ 多线程笔记3
实现简易线程池
2025-08-04
C++ 多线程笔记2
使用 condition_variable 实现生产者与消费者模型
2025-08-02
C++ 多线程笔记1
使用 call_once 解决单例模式线程安全问题
评论